1 LandR Biomass_core Module


1.1 Module Overview
1.1.2 Summary
LandR Biomass_core (hereafter Biomass_core) is the core forest succession
simulation module of the LandR ecosystem of SpaDES modules (see Chubaty & McIntire 2019). It simulates tree cohort ageing, growth, mortality and
competition for light resources, as well as seed dispersal (Fig.
1.1), in a spatially explicit manner and using a yearly
time step. The model is based on the LANDIS-II Biomass Succession Extension
v.3.2.1 (LBSE, Scheller & Miranda 2015b), with a few changes (see Differences
between Biomass_core and LBSE). Nonetheless, the
essential functioning of the succession model still largely follows its
LANDIS-II counterpart, and we refer the reader to the corresponding LBSE manual
(Scheller & Miranda 2015b) for a detailed reading of the mechanisms implemented in
the model.
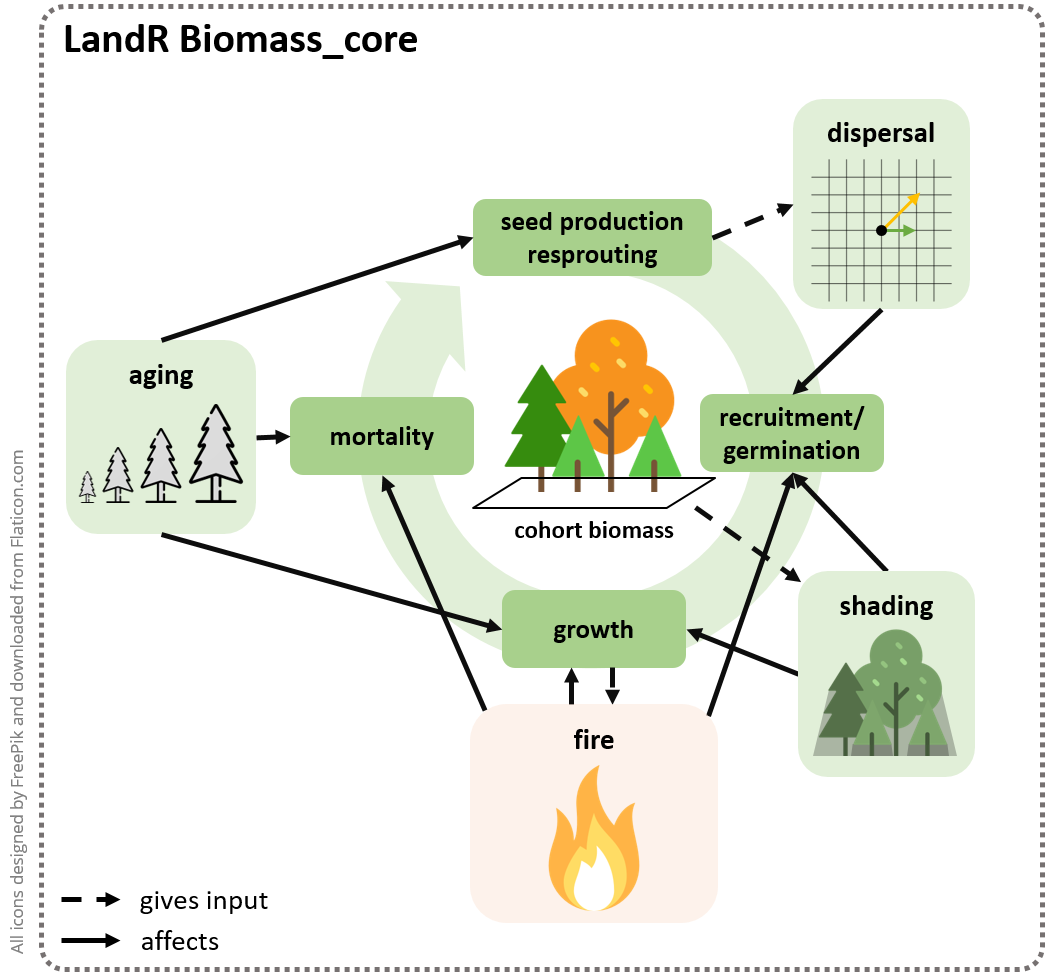
Figure 1.1: Biomass_core simulates tree cohort growth, mortality, recruitment and dispersal dynamics, as a function of cohort ageing and competition for light (shading) and space, as well as disturbances like fire (simulated using other modules).
1.1.3 Links to other modules
Biomass_core is intended to be used with data/calibration modules, disturbance
modules and validation modules, amongst others. The following is a list of the
modules most commonly used with Biomass_core. For those not yet in the LandR
Manual see the individual module’s
documentation (.Rmd file) available in its repository.
See here for all available modules and select Biomass_core from the drop-down menu to see linkages.
Data and calibration modules:
Biomass_speciesData: grabs and merges several sources of species cover data, making species percent cover (% cover) layers used by other LandR Biomass modules. Default source data spans the entire Canadian territory;
Biomass_borealDataPrep: prepares all parameters and inputs (including initial landscape conditions) that Biomass_core needs to run a realistic simulation. Default values/inputs produced are relevant for boreal forests of Western Canada;
Biomass_speciesParameters: calibrates four-species level traits using permanent sample plot data (i.e., repeated tree biomass measurements) across Western Canada.
Disturbance-related modules:
Biomass_regeneration: simulates cohort biomass responses to stand-replacing fires (as in LBSE), including cohort mortality and regeneration through resprouting and/or serotiny;
Biomass_regenerationPM: like Biomass_regeneration, but allowing partial mortality. Based on the LANDIS-II Dynamic Fuels & Fire System extension (Sturtevant et al. 2018);
fireSense: climate- and land-cover-sensitive fire model simulating fire ignition, escape and spread processes as a function of climate and land-cover. Includes built-in parameterisation of these processes using climate, land-cover, fire occurrence and fire perimeter data. Requires using Biomass_regeneration or Biomass_regenerationPM. See modules prefixed “fireSense_” at https://github.com/PredictiveEcology/;
LandMine: wildfire ignition and cover-sensitive wildfire spread model based on a fire return interval input. Requires using Biomass_regeneration or Biomass_regenerationPM;
scfm: spatially explicit fire spread module parameterised and modelled as a stochastic three-part process of ignition, escape, and spread. Requires using Biomass_regeneration or Biomass_regenerationPM.
Validation modules:
- Biomass_validationKNN: calculates two validation metrics (mean absolute deviation and sum of negative log-likelihoods) on species presences/absences and biomass-related properties across the simulated landscape. By default, it uses an independent dataset of species % cover and stand biomass for 2011, assuming that this is a second snapshot of the landscape.
1.2 Module manual
1.2.1 General functioning
Biomass_core is a forest landscape model based on the LANDIS-II Biomass
Succession Extension v.3.2.1 model (LBSE, Scheller & Miranda 2015b). It is the core
forest succession model of the LandR ecosystem of SpaDES modules. Similarly to
LBSE, Biomass_core simulates changes in tree cohort aboveground biomass
(\(g/m^2\)) by calculating growth, mortality and recruitment as functions of pixel
and species characteristics, competition and disturbances (Fig.
1.1). Note that, by default, cohorts are unique
combinations of species and age, but this can be changed via the
cohortDefinitionCols parameter (see List of parameters).
Specifically, cohort growth is driven by both invariant (growth shape parameter,
growthcurve) and spatio-temporally varying species traits (maximum biomass,
maxB, and maximum annual net primary productivity, maxANPP), while
background mortality (i.e., not caused by disturbances) depends only on
invariant species traits (longevity and mortality shape parameter,
mortalityshape). All these five traits directly influence the realised shape
of species growth curves, by determining how fast they grow (growthcurve and
maxANPP), how soon age mortality starts with respect to longevity
(mortalityshape) and the biomass a cohort can potentially achieve (maxB).
Cohort recruitment is determined by available “space” (i.e., pixel shade),
invariant species traits (regeneration mode, postfireregen, age at maturity,
sexualmature, shade tolerance, shadetolerance) and a third spatio-temporally
varying trait (species establishment probability, establishprob, called SEP
hereafter). The available “growing space” is calculated as the species’ maxB
minus the occupied biomass (summed across other cohorts in the pixel). If there
is “space”, a cohort can establish from one of three recruitment modes:
serotiny, resprouting and germination.
Disturbances (e.g., fire) can cause cohort mortality and trigger post-disturbance regeneration. Two post-disturbance regeneration mechanisms have been implemented, following LBSE: serotiny and resprouting (Scheller & Miranda 2015b). Post-disturbance mortality and regeneration only occur in response to fire and are simulated in two separate, but interchangeable modules, Biomass_regeneration and Biomass_regenerationPM that differ with respect to the level of post-fire mortality they simulate (complete or partial mortality, respectively).
Cohort germination (also called cohort establishment) occurs if seeds are available from local sources (the pixel), or via seed dispersal. Seed dispersal can be of three modes: ‘no dispersal’, ‘universal dispersal’ (arguably, only interesting for dummy case studies) or ‘ward dispersal’ (Scheller & Miranda 2015b). Briefly, the ‘ward dispersal’ algorithm describes a flexible kernel that calculates the probability of a species colonising a neighbour pixel as a function of distance from the source and dispersal-related (and invariant) species traits, and is used by default.
Finally, both germination and regeneration success depend on the species’ probability of germination in a given pixel (probabilities of germination).
We refer the reader to Scheller & Miranda (2015b), Scheller & Domingo (2011) and Scheller & Domingo (2012) for further details with respect to the above mentioned mechanisms implemented in Biomass_core. In a later section of this manual, we highlight existing differences between Biomass_core and LBSE, together with comparisons between the two modules.
1.2.2 Initialisation, inputs and parameters
To initialise and simulate forest dynamics in any given landscape, Biomass_core requires a number of inputs and parameters namely:
initial cohort biomass and age values across the landscape;
invariant species traits values;
spatio-temporally varying species traits values (or just spatially-varying);
and the probabilities of germination given a species’ shade tolerance and site shade.
These are detailed below and in the full list of input objects. The Biomass_borealDataPrep module manual also provides information about the estimation of many of these traits/inputs from available data, or their adjustment using published values or our best knowledge of boreal forest dynamics in Western Canada.
Unlike the initialisation in LBSE1, Biomass_core initialises the simulation using data-derived initial cohort biomass and age. This information is ideally supplied by data and calibration modules like Biomass_borealDataPrep (Links to other modules), but Biomass_core can also initialise itself using theoretical data.
Similarly, although Biomass_core can create all necessary traits and parameters using theoretical values, for realistic simulations these should be provided by data and calibration modules, like Biomass_borealDataPrep and Biomass_speciesParameters. We advise future users and developers to become familiar with these data modules and then try to create their own modules (or modify existing ones) for their purpose.
1.2.2.1 Initial cohort biomass and age
Initial cohort biomass and age are derived from stand biomass (biomassMap
raster layer), stand age (standAgeMap raster layer) and species %
cover (speciesLayers raster layers) data (see Table
1.5) and formatted into the cohortData
object. The cohortData table is a central simulation object that tracks the
current year’s cohort biomass, age, mortality (lost biomass) and aboveground net
primary productivity (ANPP) per species and pixel group (pixelGroup). At the
start of the simulation, cohortData will not have any values of cohort
mortality or ANPP.
Each pixelGroup is a collection of pixels that share the same ecolocation
(coded in the ecoregionMap raster layer) and the same cohort composition. By
default, an ecolocation is a combination of land-cover and ecological zonation
(see ecoregionMap in the full list of inputs) and unique
cohort compositions are defined as unique combinations of species, age and
biomass. The cohortData table is therefore always associated with the current
year’s pixelGroupMap raster layer, which provides the spatial location of all
pixelGroups, allowing to “spatialise” cohort information and dynamics (e.g.,
dispersal) on a pixel by pixel basis (see also
Hashing).
The user, or another module, may provide initial cohortData and
pixelGroupMap objects to start the simulation, or the input objects necessary
to produce them: a study area polygon (studyArea), the biomassMap,
standAgeMap, speciesLayers and ecoregionMap raster layers (see the list
of input objects for more detail).
1.2.2.2 Invariant species traits
These are spatio-temporally constant traits that mostly influence population dynamics (e.g., growth, mortality, dispersal) and responses to fire (fire tolerance and regeneration).
By default, Biomass_core obtains trait values from available LANDIS-II tables
(see Table 1.5), but traits can be
adjusted/supplied by the user or by other modules. For instance, using
Biomass_borealDataPrep will adjust some trait values for Western Canadian
boreal forests (e.g., longevity values are adjusted following Burton & Cumming 1995a), while using Biomass_speciesParameters calibrates the
growthcurve and mortalityshape parameters and estimates two additional
species traits (inflationFactor and mANPPproportion) to calibrate maxB and
maxANPP (respectively).
Table 1.1 shows an example of a table of invariant
species traits. Note that Biomass_core (alone) requires all the columns Table
1.1 in to be present, with the exception of
firetolerance, postfireregen, resproutprob, resproutage_min and
resproutage_max, which are used by the post-fire regeneration modules
(Biomass_regeneration and Biomass_regenerationPM).
Please see Scheller & Domingo (2011) and Scheller & Miranda (2015b) for further detail.
| speciesCode | longevity | sexualmature | shadetolerance | firetolerance | postfireregen | resproutprob | resproutage_min | resproutage_max | seeddistance_eff | seeddistance_max | mortalityshape | growthcurve |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Abie_sp | 200 | 20 | 2.3 | 1 | none | 0.0 | 0 | 0 | 25 | 100 | 15 | 0 |
| Pice_eng | 460 | 30 | 2.1 | 2 | none | 0.0 | 0 | 0 | 30 | 250 | 15 | 1 |
| Pice_gla | 400 | 30 | 1.6 | 2 | none | 0.0 | 0 | 0 | 100 | 303 | 15 | 1 |
| Pinu_sp | 150 | 15 | 1.0 | 2 | serotiny | 0.0 | 0 | 0 | 30 | 100 | 15 | 0 |
| Popu_sp | 140 | 20 | 1.0 | 1 | resprout | 0.5 | 10 | 70 | 200 | 5000 | 25 | 0 |
| Pseu_men | 525 | 25 | 2.0 | 3 | none | 0.0 | 0 | 0 | 100 | 500 | 15 | 1 |
1.2.2.3 Spatio-temporally varying species traits
These traits vary between species, by ecolocation and, potentially, by year if
the year column is not omitted and several years exist (in which case last
year’s values up to the current simulation year are always used). They are
maximum biomass, maxB, maximum above-ground net primary productivity,
maxANPP, and species establishment probability, SEP (called establishprob in
the module). By default, Biomass_core assigns theoretical values to these
traits, and thus we recommend using Biomass_borealDataPrep to obtain realistic
trait values derived from data (by default, pertinent for Canadian boreal forest
applications), or passing a custom table directly. Biomass_speciesParameters
further calibrates maxB and maxANPP by estimating two additional invariant
species traits (inflationFactor and mANPPproportion; also for Western
Canadian forests). See Table 1.2 for an example.
| ecoregionGroup | speciesCode | establishprob | maxB | maxANPP | year |
|---|---|---|---|---|---|
| 1_03 | Abie_sp | 1.000 | 8567 | 285 | 1 |
| 1_03 | Pice_eng | 0.983 | 10156 | 305 | 1 |
| 1_03 | Popu_sp | 0.737 | 8794 | 293 | 1 |
| 1_03 | Pseu_men | 1.000 | 17534 | 132 | 1 |
| 1_09 | Abie_sp | 0.112 | 1499 | 50 | 1 |
| 1_09 | Pice_gla | 0.302 | 3143 | 102 | 1 |
| 1_09 | Pinu_sp | 0.714 | 2569 | 86 | 1 |
| 1_09 | Popu_sp | 0.607 | 3292 | 110 | 1 |
| 1_09 | Pseu_men | 0.997 | 6020 | 45 | 1 |
| 1_03 | Abie_sp | 0.989 | 8943 | 225 | 2 |
| 1_03 | Pice_eng | 0.985 | 9000 | 315 | 2 |
| 1_03 | Popu_sp | 0.600 | 8600 | 273 | 2 |
| 1_03 | Pseu_men | 1.000 | 13534 | 142 | 2 |
| 1_09 | Abie_sp | 0.293 | 2099 | 45 | 2 |
| 1_09 | Pice_gla | 0.745 | 3643 | 90 | 2 |
| 1_09 | Pinu_sp | 0.500 | 2569 | 80 | 2 |
| 1_09 | Popu_sp | 0.670 | 3262 | 111 | 2 |
| 1_09 | Pseu_men | 1.000 | 6300 | 43 | 2 |
1.2.2.4 Ecolocation-specific parameters – minimum relative biomass
Minimum relative biomass (minRelativeB) is the only ecolocation-specific
parameter used in Biomass_core. It is used to determine the shade level in
each pixel (i.e., site shade) with respect to the total potential maximum
biomass for that pixel (i.e., the sum of all maxB values in the pixel’s
ecolocation). If relative biomass in the stand (with regards to the total
potential maximum biomass) is above the minimum relative biomass thresholds, the
pixel is assigned that threshold’s site shade value (Scheller & Miranda 2015b).
The shade level then influences the germination and regeneration of new cohorts, depending on their shade tolerance (see Probabilities of germination).
Site shade varies from X0 (no shade) to X5 (maximum shade). By default, Biomass_core uses the same minimum realtive biomass threshold values across all ecolocations, adjusted from a publicly available LANDIS-II table to better reflect Western Canada boreal forest dynamics (see Table 1.3). Biomass_borealDataPrep does the same adjustment by default. As with other inputs, these values can be adjusted by using other modules or by passing user-defined tables.
| ecoregionGroup | |||||
|---|---|---|---|---|---|
| 1_03 | 0.15 | 0.25 | 0.5 | 0.75 | 0.85 |
| 1_09 | 0.15 | 0.25 | 0.5 | 0.75 | 0.85 |
1.2.2.5 Probabilities of germination
A species’ probability of germination results from the combination of its shade
tolerance level (an invariant species trait in the species table; Table
1.1) and the site shade (defined by the amount of
biomass in the pixel – see minimum relative biomass
parameter and Scheller & Miranda 2015b). By default, both
Biomass_core and Biomass_borealDataPrep use a publicly available LANDIS-II
table (called sufficientLight in the module; Table 1.4).
| species shade tolerance | X0 | X1 | X2 | X3 | X4 | X5 |
|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 1 | 0 | 0 | 0 | 0 |
| 3 | 1 | 1 | 1 | 0 | 0 | 0 |
| 4 | 1 | 1 | 1 | 1 | 0 | 0 |
| 5 | 0 | 0 | 1 | 1 | 1 | 1 |
1.2.2.6 Other module inputs
The remaining module input objects either do not directly influence the basic
mechanisms implemented in Biomass_core (e.g., sppColorVect and
studyAreaReporting are only used for plotting purposes), are objects that keep
track of a property/process in the module (e.g., lastReg is a counter of the
last year when regeneration occurred), or define the study area for the
simulation (e.g., studyArea and rasterToMatch).
The next section provides a complete list of all input objects, including those already mentioned above.
1.2.3 List of input objects
All of Biomass_core’s input objects have (theoretical) defaults that are
produced automatically by the module2. We suggest that new users
run Biomass_core by itself supplying only a studyArea polygon, before
attempting to supply their own or combining Biomass_core with other modules.
This will enable them to become familiar with all the input objects in a
theoretical setting.
Of the inputs listed in Table 1.5, the following are particularly important and deserve special attention:
Spatial layers
ecoregionMap– a raster layer with ecolocation IDs. Note that the term “ecoregion” was inherited from LBSE and kept for consistency with original LBSE code, but we prefer to call them ecolocations to avoid confusion with the ecoregion-level classification of the National Ecological Classification of Canada (NECC). Ecolocations group pixels with similar biophysical conditions. By default, we use two levels of grouping in our applications: the first level being an ecological classification such as ecodistricts from the NECC, and the second level is a land-cover classification. Hence, these ecolocations contain relatively coarse scale regional information plus finer scale land cover information. TheecoregionMaplayer must be defined as a categorical raster, with an associated Raster Attribute Table (RAT; see, e.g.,raster::ratify). The RAT must contain the columns:ID(the value in the raster layer),ecoregion(the first level of grouping) andecoregionGroup(the full ecolocation “name” written as <firstlevel_secondlevel>). Note that if creatingecoregionGroup’s by combining two raster layers whose values are numeric (as in Biomass_borealDataPrep), the group label is a character combination of two numeric grouping levels. For instance, if Natural Ecoregion2has land-cover types1,2and3, the RAT will containID = {1,2,3},ecoregion = {2}andecoregionGroup = {2_1, 2_2, 2_3}. However, the user is free to use any groupings they wish. Finally, note that all ecolocations (ecoregionGroup’s) are should be listed in theecoregiontable.rasterToMatch– a RasterLayer, with a given resolution and projection determining the pixels (i.e., non-NA values) where forest dynamics will be simulated. Needs to matchstudyArea. If not supplied, Biomass_core attempts to produce it fromstudyArea, usingbiomassMapas the template for spatial resolution and projection.studyArea– aSpatialPolygonsDataFramewith a single polygon determining the where the simulation will take place. This is the only input object that must be supplied by the user or another module.
Species traits and other parameter tables
ecoregion– adata.tablelisting all ecolocation “names” (ecoregionGroup column; seeecoregionMapabove for details) and their state (active –yes– or inactive –no)minRelativeB– adata.tableof minimum relative biomass values. See Ecolocation-specific parameters – minimum relative biomass.species– adata.tableof invariant species traits.speciesEcoregion– adata.tableof spatio-temporally varying species traits.sufficientLight– adata.tabledefining the probability of germination for a species, given itsshadetolerancelevel (seespeciesabove) and the shade level in the pixel (seeminRelativeBabove). See Probabilities of germination.sppEquiv– adata.tableof species name equivalences between various conventions. It must contain the columns LandR (species IDs in the LandR format), EN_generic_short (short generic species names in English – or any other language – used for plotting), Type (type of species, Conifer or Deciduous, as in “broadleaf”) and Leading (same as EN_generic_short but with “leading” appended – e.g., “Poplar leading”). See?LandR::sppEquivalencies_CAfor more information.sppColorVect– character. A named vector of colours used to plot species dynamics. Should contain one colour per species in thespeciestable and, potentially a colour for species mixtures (named “Mixed”). Vector names must followspecies$speciesCode.
Cohort-simulation-related objects
-
cohortData– adata.tablecontaining initial cohort information perpixelGroup(seepixelGroupMapbelow). This table is updated during the simulation as cohort dynamics are simulated. It must contain the following columns:pixelGroup – integer. pixelGroup ID. See Hashing.
ecoregionGroup – character. Ecolocation names. See
ecoregionMapandecoregionobjects above.speciesCode – character. Species ID.
age – integer. Cohort age.
B – integer. Cohort biomass of the current year in \(g/m^2\).
mortality – integer. Cohort dead biomass of the current year in \(g/m^2\). Usually filled with 0s in initial conditions.
aNPPAct – integer. Actual aboveground net primary productivity of the current year in \(g/m^2\).
Bis the result of the previous year’sBminus the current year’smortalityplusaNPPAct. Usually filled with 0s in initial conditions. See “1.1.3 Cohort growth and ageing” section of Scheller & Miranda (2015b).
pixelGroupMap– a raster layer withpixelGroupIDs per pixel. Pixels are always grouped based on identicalecoregionGroup,speciesCode,ageandBcomposition, even if the user supplies other initial groupings (e.g., this is possible in the Biomass_borealDataPrep data module).
| objectName | objectClass | desc | sourceURL |
|---|---|---|---|
| biomassMap | RasterLayer |
total biomass raster layer in study area (in g/m^2), filtered for pixels covered by cohortData. Only used if P(sim)$initialBiomassSource == 'biomassMap', which is currently deactivated.
|
|
| cceArgs | list |
a list of quoted objects used by the growthAndMortalityDriver calculateClimateEffect function
|
NA |
| cohortData | data.table |
data.table with cohort-level information on age and biomass, by pixelGroup and ecolocation (i.e., ecoregionGroup). If supplied, it must have the following columns: pixelGroup (integer), ecoregionGroup (factor), speciesCode (factor), B (integer in g/m^2), age (integer in years)
|
NA |
| ecoregion | data.table | ecoregion look up table | https://raw.githubusercontent.com/LANDIS-II-Foundation/Extensions-Succession/master/biomass-succession-archive/trunk/tests/v6.0-2.0/ecoregions.txt |
| ecoregionMap | RasterLayer |
ecoregion map that has mapcodes match ecoregion table and speciesEcoregion table. Defaults to a dummy map matching rasterToMatch with two regions
|
NA |
| lastReg | numeric | an internal counter keeping track of when the last regeneration event occurred | NA |
| minRelativeB | data.frame | table defining the relative biomass cut points to classify stand shadeness. | NA |
| pixelGroupMap | RasterLayer |
a raster layer with pixelGroup IDs per pixel. Pixels are grouped based on identical ecoregionGroup, speciesCode, age and B composition, even if the user supplies other initial groupings (e.g., via the Biomass_borealDataPrep module.
|
NA |
| rasterToMatch | RasterLayer |
a raster of the studyArea in the same resolution and projection as biomassMap
|
NA |
| species | data.table | a table of invariant species traits with the following trait colums: ‘species’, ‘Area’, ‘longevity’, ‘sexualmature’, ‘shadetolerance’, ‘firetolerance’, ‘seeddistance_eff’, ‘seeddistance_max’, ‘resproutprob’, ‘mortalityshape’, ‘growthcurve’, ‘resproutage_min’, ‘resproutage_max’, ‘postfireregen’, ‘wooddecayrate’, ‘leaflongevity’ ‘leafLignin’, ‘hardsoft’. The last seven traits are not used in Biomass_core , and may be ommited. However, this may result in downstream issues with other modules. Default is from Dominic Cyr and Yan Boulanger’s project | https://raw.githubusercontent.com/dcyr/LANDIS-II_IA_generalUseFiles/master/speciesTraits.csv |
| speciesEcoregion | data.table |
table of spatially-varying species traits (maxB, maxANPP, establishprob), defined by species and ecoregionGroup) Defaults to a dummy table based on dummy data os biomass, age, ecoregion and land cover class
|
NA |
| speciesLayers | RasterStack | percent cover raster layers of tree species in Canada. Defaults to the Canadian Forestry Service, National Forest Inventory, kNN-derived species cover maps from 2001 using a cover threshold of 10 - see https://open.canada.ca/data/en/dataset/ec9e2659-1c29-4ddb-87a2-6aced147a990 for metadata | http://ftp.maps.canada.ca/pub/nrcan_rncan/Forests_Foret/canada-forests-attributes_attributs-forests-canada/2001-attributes_attributs-2001/ |
| sppColorVect | character |
A named vector of colors to use for plotting. The names must be in sim$sppEquiv[[sim$sppEquivCol]], and should also contain a color for ‘Mixed’
|
NA |
| sppEquiv | data.table |
table of species equivalencies. See LandR::sppEquivalencies_CA.
|
NA |
| studyArea | SpatialPolygonsDataFrame | Polygon to use as the study area. Must be provided by the user | NA |
| studyAreaReporting | SpatialPolygonsDataFrame |
multipolygon (typically smaller/unbuffered than studyArea) to use for plotting/reporting. Defaults to studyArea.
|
NA |
| sufficientLight | data.frame | table defining how the species with different shade tolerance respond to stand shade. Default is based on LANDIS-II Biomass Succession v6.2 parameters | https://raw.githubusercontent.com/LANDIS-II-Foundation/Extensions-Succession/master/biomass-succession-archive/trunk/tests/v6.0-2.0/biomass-succession_test.txt |
| treedFirePixelTableSinceLastDisp | data.table |
3 columns: pixelIndex, pixelGroup, and burnTime. Each row represents a forested pixel that was burned up to and including this year, since last dispersal event, with its corresponding pixelGroup and time it occurred
|
NA |
1.2.4 List of parameters
In addition to the above inputs objects, Biomass_core uses several
parameters3 that control aspects like the simulation length, the
“succession” time step, plotting and saving intervals, amongst others. Note that
a few of these parameters are only relevant when simulating climate effects of
cohort growth and mortality, which require also loading the LandR.CS R
package4 (or another similar package). These are not discussed
in detail here, since climate effects are calculated externally to
Biomass_core in LandR.CS functions and thus documented there.
A list of useful parameters and their description is listed below, while the
full set of parameters is in Table 1.6. Like
with input objects, default values are supplied for all parameters and we
suggest the user becomes familiarized with them before attempting any changes.
We also note that the "spin-up" and "biomassMap" options for the
initialBiomassSource parameter are currently deactivated, since Biomass_core
no longer generates initial cohort biomass conditions using a spin-up based on
initial stand age like LANDIS-II ("spin-up"), nor does it attempt to fill
initial cohort biomasses using biomassMap.
Plotting and saving
.plots– activates/deactivates plotting and defines type of plotting (see?Plots);.plotInitialTime– defines when plotting starts;.plotInterval– defines plotting frequency;.plotMaps– activates/deactivates map plotting;.saveInitialTime– defines when saving starts;.saveInterval– defines saving frequency;
Simulation
seedingAlgorithm– dispersal type (see above);successionTimestep– defines frequency of dispersal/local recruitment event (growth and mortality are always yearly);
Other
mixedType– how mixed forest stands are defined;vegLeadingProportion– relative biomass threshold to consider a species “leading” (i.e., dominant);
| paramName | paramClass | default | min | max | paramDesc |
|---|---|---|---|---|---|
| calcSummaryBGM | character | end | NA | NA | A character vector describing when to calculate the summary of biomass, growth and mortality Currently any combination of 5 options is possible: ‘start’- as before vegetation succession events, i.e. before dispersal, ‘postDisp’ - after dispersal, ‘postRegen’ - after post-disturbance regeneration (currently the same as ‘start’), ‘postGM’ - after growth and mortality, ‘postAging’ - after aging, ‘end’ - at the end of vegetation succesion events, before plotting and saving. The ‘end’ option is always active, being also the default option. If NULL, then will skip all summaryBGM related events |
| calibrate | logical | FALSE | NA | NA |
Do calibration? Defaults to FALSE
|
| cohortDefinitionCols | character | pixelGro…. | NA | NA |
cohortData columns that determine what constitutes a cohort This parameter should only be modified if additional modules are adding columns to cohortData
|
| cutpoint | numeric | 1e+10 | NA | NA | A numeric scalar indicating how large each chunk of an internal data.table is, when processing by chunks |
| gmcsGrowthLimits | numeric | 66.66666…. | NA | NA |
if using LandR.CS for climate-sensitive growth and mortality, a percentile is used to estimate the effect of climate on growth/mortality (currentClimate/referenceClimate). Upper and lower limits are suggested to circumvent problems caused by very small denominators as well as predictions outside the data range used to generate the model
|
| gmcsMortLimits | numeric | 66.66666…. | NA | NA |
if using LandR.CS for climate-sensitive growth and mortality, a percentile is used to estimate the effect of climate on growth/mortality (currentClimate/referenceClimate). Upper and lower limits are suggested to circumvent problems caused by very small denominators as well as predictions outside the data range used to generate the model
|
| gmcsMinAge | numeric | 21 | 0 | NA |
if using LandR.CS for climate-sensitive growth and mortality, the minimum age for which to predict climate-sensitive growth and mortality. Young stands (< 30) are poorly represented by the PSP data used to parameterize the model.
|
| growthAndMortalityDrivers | character | LandR | NA | NA |
package name where the following functions can be found: calculateClimateEffect, assignClimateEffect (see LandR.CS for climate sensitivity equivalent functions, or leave default if this is not desired)
|
| growthInitialTime | numeric | start(sim) | NA | NA | Initial time for the growth event to occur |
| initialB | numeric | 10 | 1 | NA | initial biomass values of new age-1 cohorts |
| initialBiomassSource | character | cohortData | NA | NA |
Currently, there are three options: ‘spinUp’, ‘cohortData’, ‘biomassMap’. If ‘spinUp’, it will derive biomass by running spinup derived from Landis-II. If ‘cohortData’, it will be taken from the cohortData object, i.e., it is already correct, by cohort. If ‘biomassMap’, it will be taken from sim$biomassMap, divided across species using sim$speciesLayers percent cover values ‘spinUp’ uses sim$standAgeMap as the driver, so biomass is an output . That means it will be unlikely to match any input information about biomass, unless this is set to ‘biomassMap’, and a sim$biomassMap is supplied. Only the ‘cohortData’ option is currently active.
|
| keepClimateCols | logical | FALSE | NA | NA |
include growth and mortality predictions in cohortData?
|
| minCohortBiomass | numeric | 0 | NA | NA | cohorts with biomass below this threshold (in g/m^2) are removed. Not a LANDIS-II BSE parameter. |
| mixedType | numeric | 2 | NA | NA |
How to define mixed stands: 1 for any species admixture; 2 for deciduous > conifer. See ?LandR::vegTypeMapGenerator.
|
| plotOverstory | logical | FALSE | NA | NA | swap max age plot with overstory biomass |
| seedingAlgorithm | character | wardDisp…. | NA | NA | choose which seeding algorithm will be used among ‘noSeeding’ (no horizontal, nor vertical seeding - not in LANDIS-II BSE), ‘noDispersal’ (no horizontal seeding), ‘universalDispersal’ (seeds disperse to any pixel), and ‘wardDispersal’ (default; seeds disperse according to distance and dispersal traits). See Scheller & Miranda (2015) - Biomass Succession extension, v3.2.1 User Guide |
| spinupMortalityfraction | numeric | 0.001 | NA | NA |
defines the mortality loss fraction in spin up-stage simulation. Only used if P(sim)$initialBiomassSource == 'biomassMap', which is currently deactivated.
|
| sppEquivCol | character | Boreal | NA | NA |
The column in sim$sppEquiv data.table to use as a naming convention
|
| successionTimestep | numeric | 10 | NA | NA | defines the simulation time step, default is 10 years. Note that growth and mortality always happen on a yearly basis. Cohorts younger than this age will not be included in competitive interactions |
| vegLeadingProportion | numeric | 0.8 | 0 | 1 | a number that defines whether a species is leading for a given pixel |
| .maxMemory | numeric | 5 | NA | NA | maximum amount of memory (in GB) to use for dispersal calculations. |
| .plotInitialTime | numeric | start(sim) | NA | NA |
Vector of length = 1, describing the simulation time at which the first plot event should occur. To plotting off completely use P(sim)$.plots.
|
| .plotInterval | numeric | NA | NA | NA |
defines the plotting time step. If NA, the default, .plotInterval is set to successionTimestep.
|
| .plots | character | object | NA | NA |
Passed to types in Plots (see ?Plots). There are a few plots that are made within this module, if set. Note that plots (or their data) saving will ONLY occur at end(sim). If NA, plotting is turned off completely (this includes plot saving).
|
| .plotMaps | logical | TRUE | NA | NA |
Controls whether maps should be plotted or not. Set to FALSE if P(sim)$.plots == NA
|
| .saveInitialTime | numeric | NA | NA | NA |
Vector of length = 1, describing the simulation time at which the first save event should occur. Set to NA if no saving is desired. If not NA, then saving will occur at P(sim)$.saveInitialTime with a frequency equal to P(sim)$.saveInterval
|
| .saveInterval | numeric | NA | NA | NA |
defines the saving time step. If NA, the default, .saveInterval is set to P(sim)$successionTimestep.
|
| .sslVerify | integer | 64 | NA | NA |
Passed to httr::config(ssl_verifypeer = P(sim)$.sslVerify) when downloading KNN (NFI) datasets. Set to 0L if necessary to bypass checking the SSL certificate (this may be necessary when NFI’s website SSL certificate is not correctly configured).
|
| .studyAreaName | character | NA | NA | NA |
Human-readable name for the study area used. If NA, a hash of studyArea will be used.
|
| .useCache | character | .inputOb…. | NA | NA |
Internal. Can be names of events or the whole module name; these will be cached by SpaDES
|
| .useParallel | ANY | 2 | NA | NA |
Used only in seed dispersal. If numeric, it will be passed to data.table::setDTthreads and should be <= 2; If TRUE, it will be passed to parallel::makeCluster; and if a cluster object, it will be passed to parallel::parClusterApplyB.
|
1.2.5 List of outputs
The main outputs of Biomass_core are the cohortData and pixelGroupMap
containing cohort information per year (note that they are not saved by
default), visual outputs of species level biomass, age and dominance across the
landscape and the simulation length, and several maps of stand biomass,
mortality and reproductive success (i.e, new biomass) on a yearly basis.
However, any of the objects changed/output by Biomass_core (listed in Table
1.7) can be saved via the outputs argument
in simInit5.
| objectName | objectClass | desc |
|---|---|---|
| activePixelIndex | integer | internal use. Keeps track of which pixels are active |
| activePixelIndexReporting | integer | internal use. Keeps track of which pixels are active in the reporting study area |
| ANPPMap | RasterLayer | ANPP map at each succession time step (in g /m^2) |
| cohortData | data.table |
data.table with cohort-level information on age, biomass, aboveground primary productivity (year’s biomass gain) and mortality (year’s biomass loss), by pixelGroup and ecolocation (i.e., ecoregionGroup). Contains at least the following columns: pixelGroup (integer), ecoregionGroup (factor), speciesCode (factor), B (integer in g/m^2), age (integer in years), mortality (integer in g/m^2), aNPPAct (integer in g/m^2). May have other columns depending on additional simulated processes (i.e., cliamte sensitivity; see, e.g., P(sim)$keepClimateCols).
|
| ecoregionMap | RasterLayer |
map with mapcodes match ecoregion table and speciesEcoregion table. Defaults to a dummy map matching rasterToMatch with two regions
|
| inactivePixelIndex | logical | internal use. Keeps track of which pixels are inactive |
| inactivePixelIndexReporting | integer | internal use. Keeps track of which pixels are inactive in the reporting study area |
| lastFireYear | numeric | Year of the most recent fire year |
| lastReg | numeric | an internal counter keeping track of when the last regeneration event occurred |
| minRelativeB | data.frame | define the relative biomass cut points to classify stand shade |
| mortalityMap | RasterLayer | map of biomass lost (in g/m^2) at each succession time step |
| pixelGroupMap | RasterLayer | updated community map at each succession time step |
| regenerationOutput | data.table |
If P(sim)$calibrate == TRUE, an summary of seed dispersal and germination success (i.e., number of pixels where seeds successfully germinated) per species and year.
|
| reproductionMap | RasterLayer | Regeneration map (biomass gains in g/m^2) at each succession time step |
| simulatedBiomassMap | RasterLayer | Biomass map at each succession time step (in g/m^2) |
| simulationOutput | data.table |
contains simulation results by ecoregionGroup (main output)
|
| simulationTreeOutput | data.table |
Summary of several characteristics about the stands, derived from cohortData
|
| species | data.table | a table that has species traits such as longevity, shade tolerance, etc. Currently obtained from LANDIS-II Biomass Succession v.6.0-2.0 inputs |
| speciesEcoregion | data.table | define the maxANPP, maxB and SEP change with both ecoregion and simulation time |
| speciesLayers | RasterStack |
species percent cover raster layers, based on input speciesLayers object. Not changed by this module.
|
| spinupOutput | data.table | Spin-up output. Currently deactivated. |
| summaryBySpecies | data.table |
The total species biomass (in g/m^2 as in cohortData), average age and aNPP (in g/m^2 as in cohortData), across the landscape (used for plotting and reporting).
|
| summaryBySpecies1 | data.table | No. pixels of each leading vegetation type (used for plotting and reporting). |
| summaryLandscape | data.table |
The averages of total biomass (in tonnes/ha , not g/m^2 like in cohortData), age and aNPP (also in tonnes/ha) across the landscape (used for plotting and reporting).
|
| treedFirePixelTableSinceLastDisp | data.table |
3 columns: pixelIndex, pixelGroup, and burnTime. Each row represents a forested pixel that was burned up to and including this year, since last dispersal event, with its corresponding pixelGroup and time it occurred
|
| vegTypeMap | RasterLayer |
Map of leading species in each pixel, colored according to sim$sppColorVect. Species mixtures calculated according to P(sim)$vegLeadingProportion and P(sim)$mixedType.
|
1.2.6 Simulation flow and module events
Biomass_core itself does not simulate disturbances or their effect on vegetation (i.e., post-disturbance mortality and regeneration). Should disturbance and post-disturbance mortality/regeneration modules be used (e.g., LandMine and Biomass_regeneration), the user should make sure that post-disturbance effects occur after the disturbance, but before dispersal and background vegetation growth and mortality (simulated in Biomass_core). Hence, the disturbance itself should take place either at the very beginning or at the very end of each simulation time step to guarantee that it happens immediately before post-disturbance effects are calculated.
The general flow of Biomass_core processes with and without disturbances is:
Preparation of necessary objects for the simulation – either by data and calibration modules or by Biomass_core itself (during
simInitand theinitevent6);Disturbances (OPTIONAL) – simulated by a disturbance module (e.g., LandMine);
Post-disturbance mortality/regeneration (OPTIONAL) – simulated by a regeneration module (e.g., Biomass_regeneration);
-
Seed dispersal (every
successionTimestep;Dispersalevent):- seed dispersal can be a slow process and has been adapted to occur every
10 years (default
successionTimestep). The user can set it to occur more/less often, with the caveat that if using Biomass_borealDataPrep to estimate species establishment probabilities, these values are integrated over 10 years. - see Scheller & Domingo (2012) for details on dispersal algorithms.
- seed dispersal can be a slow process and has been adapted to occur every
10 years (default
-
Growth and mortality (
mortalityAndGrowthevent):- unlike dispersal, growth and mortality always occur time step (year).
- see Scheller & Mladenoff (2004) for further detail.
-
Cohort age binning (every
successionTimestep;cohortAgeReclassificationevent):- follows the same frequency as dispersal, collapsing cohorts (i.e.,
summing their biomass/mortality/aNPP) to ages classes with resolution
equal to
successionTimestep. - see Scheller & Miranda (2015b) for further detail.
- follows the same frequency as dispersal, collapsing cohorts (i.e.,
summing their biomass/mortality/aNPP) to ages classes with resolution
equal to
Summary tables of regeneration (
summaryRegenevent), biomass, age, growth and mortality (summaryBGMevent);Plots of maps (
plotMapsevent) and averages (plotAvgsandplotSummaryBySpeciesevents);Save outputs (
saveevent).
… (repeat 2-9) …
1.2.7 Differences between Biomass_core and the LANDIS-II Biomass Succession Extension model (LBSE)
1.2.7.1 Algorithm changes
Upon porting LBSE into R, we made six minor modifications to the original model’s algorithms to better reflect ecological processes. This did not significantly alter the simulation outputs and we note that these changes might also have been implemented in more recent versions of LBSE.
First, for each year and community (i.e., ‘pixel group’ in Biomass_core, see below), LBSE calculates the competition index for a cohort sequentially (i.e., one cohort at a time) after updating the growth and mortality of other cohorts (i.e., their biomass gain and loss, respectively) , and with the calculation sequence following cohort age in descending order, but no explicit order of species. This sorting of growth and mortality calculations from oldest to youngest cohorts in LBSE was aimed at capturing size-asymmetric competition between cohorts, under the assumption that older cohorts have priority for growing space given their greater height (Scheller pers. comm.). We felt that within-year sequential growth, death and recruitment may be not ecologically accurate, and that the size-asymmetric competition was being accounted for twice, as the calculation of the competition index already considers the competitive advantage of older cohorts (as shown in the User’s Guide, Scheller & Miranda 2015b). Hence, in Biomass_core growth, mortality, recruitment and the competition index are calculated at the same time across all cohorts and species.
Second, the unknown species-level sorting mechanism contained within LBSE (which changed depending on the species order in the input species list file), led to different simulation results depending on the input species list file (e.g., Table 1.8 and Fig. 1.2). The calculation of competition, growth and mortality for all cohorts at the same time also circumvented this issue.
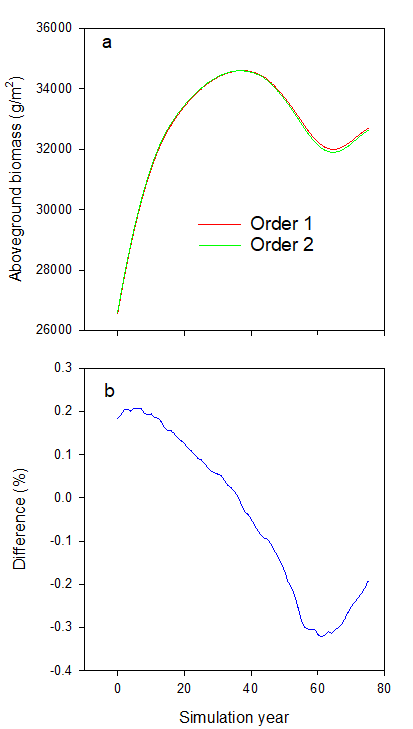
Figure 1.2: Differences in total landscape aboveground biomass when using two different input species orders for the same community. These simulations demonstrate how the sequential calculation of the competition index, combined with a lack of explicit species ordering affect the overall landscape aboveground biomass in time when using different input species orders (see Table 1.8). In order to prevent differences introduced by cohort recruitment, species’ ages at sexual maturity were changed to the species’ longevity values, and the simulation ran for 75 years to prevent any cohorts from reaching sexual maturity. The bottom panel shows the difference between the two simulations in percentage, calculated as \(\frac{Biomass_{order2} - Biomass_{order1}}{Biomass_{order2}} * 100\)
Third, in LBSE the calculation of total pixel biomass for the purpose of calculating the initial biomass of a new cohort included the (previously calculated) biomass of other new cohorts when succession time step = 1, but not when time step was > 1. This does not reflect the documentation in the User’s Guide, which stated that “Bsum [total pixel biomass] is the current total biomass for the site (not including other new cohorts)” (Scheller & Miranda 2015b), when the succession time step was set to 1. Additionally, together with the lack of explicit ordering, this generated different results in terms of the biomass assigned to each new cohort (e.g., Table 1.9 and Fig. 1.3). In Biomass_core the initial biomass of new cohorts is no longer calculated sequentially (as with competition, growth and mortality), and thus the biomass of new cohorts is never included in the calculation of total pixel biomass.
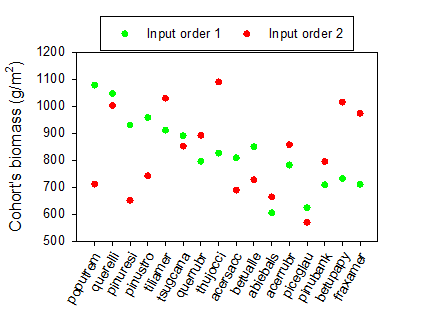
Figure 1.3: Differences in the biomass assigned to new cohorts, summed for each species across pixels, when using two different input species orders for the same community and when the succession time step is 1. These simulations demonstrate how the different summation of total cohort biomass for a succession time step of 1 and the lack of explicit species ordering affect simulation results when changing the species order in the input file (see Table 1.9). Here, initial cohort ages were also set to 1. Values refer to the initial total biomass attributed to each species at the end of year 1.
Fourth, in LBSE, serotiny and resprouting could not occur in the same pixel following a fire, with serotiny taking precedence if activated. We understand that this provides an advantage to serotinous species, which could perhaps be disadvantaged with respect to fast-growing resprouters. However, we feel that it is ecologically more realistic that serotinous and resprouter species be able to both regenerate in a given pixel following a fire and allow the competition between serotinous and resprouting species to arise from species traits. Note that this change was implemented in the Biomass_regeneration and Biomass_regenerationPM modules, since post-disturbance effects were separated background vegetation dynamics simulated by Biomass_core.
Fifth, in Biomass_core, species shade tolerance values can have decimal values to allow for finer adjustments of between-species competition.
Sixth, we added a new parameter called minCohortBiomass, that allows the user
to control cohort removal bellow a certain threshold of biomass. In some
simulation set-ups, we noticed that Biomass_core (and LBSE) were able to
generate many very small cohorts in the understory that, due to cohort
competition, were not able to gain biomass and grow. However, because
competition decreases growth but does not increase mortality, these cohorts
survived at very low biomass levels until they reached sufficient age to suffer
age-related mortality. We felt this is unlikely to be realistic in many cases.
By default, this parameter is left at 0 to follow LBSE behaviour (i.e., no
cohorts removal based on minimum biomass).
1.2.7.2 Other enhancements
In addition to the sixth changes in growth, mortality and regeneration mentioned above, we enhanced modularity by separating the components that govern vegetation responses to disturbances from Biomass_core, and implemented hashing, caching and testing to improve computational efficiency and insure performance.
1.2.7.2.1 Modularity
Unlike in LBSE, post-disturbance effects are not part of Biomass_core per se, but belong to two separate modules, used interchangeably (Biomass_regeneration and Biomass_regenerationPM). These need to be loaded and added to the “modules folder” of the project in case the user wants to simulate forest responses to disturbances (only fire disturbances at the moment). Again, this enables higher flexibility when swapping between different approaches to regeneration.
Climate effects on growth and mortality were also implemented a modular way. The
effects of climate on biomass increase (growth) and loss (mortality) were
written in functions grouped in two packages. The LandR R package contains
default, “non-climate-sensitive” functions, while the LandR.CS R package
contains the functions that simulate climate effects (CS stands for “climate
sensitive”). Note that these functions do not simulate actual growth/mortality
processes, but estimate modifiers that increase/decrease cohort biomass on top
of background growth/mortality. Biomass_core uses the LandR functions by
default (see growthAndMortalityDrivers parameter in the full parameters
list). Should the user wish to change how climate effects on
growth/mortality are calculated, they can provide new compatible functions
(i.e., with the same names, inputs and outputs) via another R package.
1.2.7.2.2 Hashing
Our first strategy to improve simulation efficiency in Biomass_core was to use a hashing mechanism (Yang et al. 2011). Instead of assigning a key to each pixel in a raster and tracking the simulation for each pixel in a lookup table, we indexed pixels using a pixelGroup key that contained unique combinations of ecolocation and community composition (i.e., species, age and biomass composition), and tracked and stored simulation data for each pixelGroup (Fig. 1.4). This algorithm was able to ease the computational burden by significantly reducing the size of the lookup table and speeding-up the simulation process. After recruitment and disturbance events, pixels are rehashed into new pixel groups.
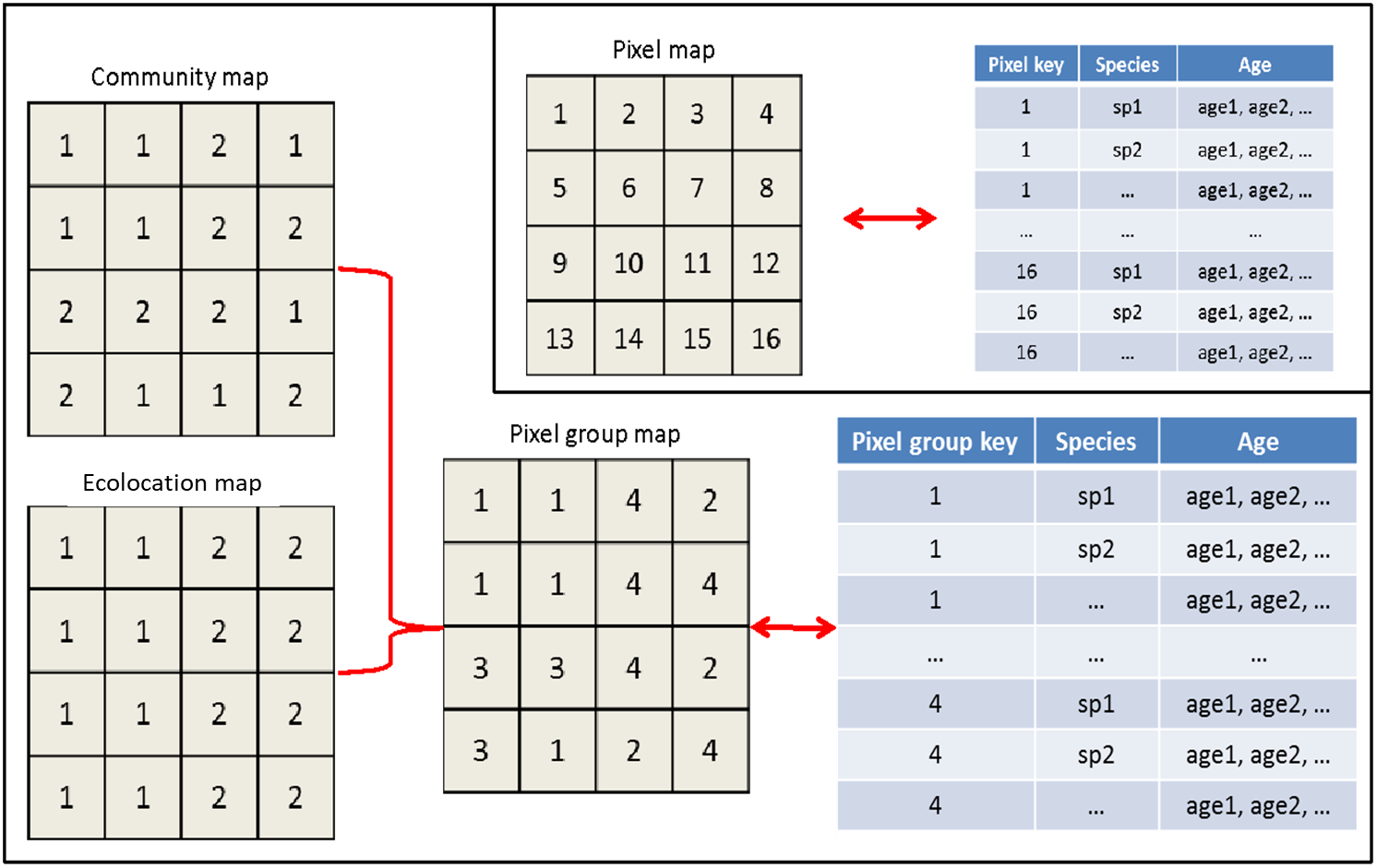
Figure 1.4: Hashing design for Biomass_core. In the re-coded Biomass_core, the pixel group map was hashed based on the unique combination of species composition (‘community map’) and ecolocation map, and associated with a lookup table. The insert in the top-right corner was the original design that linked the map to the lookup table by pixel key.
1.2.7.2.3 Caching
The second strategy aimed at improving model efficacy was the implementation of
caching during data-driven parametrisation and initialisation. Caching
automatically archives outputs of a given function to disk (or memory) and reads
them back when subsequent calls of this function are given identical inputs. All
caching operations were achieved using the reproducible R package
(McIntire & Chubaty 2020).
In the current version of Biomass_core, the spin-up phase was replaced by data-driven landscape initialisation and many model parameters were derived from data, using data and calibration modules (e.g., Biomass_borealDataPrep). To avoid having to repeat data downloads and treatment, statistical estimation of parameters and landscape initialisation every time the simulation is re-run under the same conditions, many of these pre-simulation steps are automatically cached. This means that the pre-simulation phase is significantly faster upon a second call when inputs have not changed (e.g., the input data and parametrisation methods), and when inputs do change only directly affected steps are re-run (see main text for examples). When not using data modules, Biomass_core still relies on caching for the preparation of its theoretical inputs.
1.2.7.2.4 Testing
Finally, we implemented code testing to facilitate bug detection by comparing
the outputs of functions (etc.) to expected outputs (Wickham 2011). We built and
integrated code tests in Biomass_core and across all LandR modules and the
LandR R package in the form of assertions,
unit tests and integration tests. Assertions and unit tests are run
automatically during simulations (but can be turned off) and evaluate individual
code components (e.g., one function or an object’s class). Integration tests
evaluate if several coded processes are integrated correctly and are usually run
manually. However, because we embedded assertions within the module code, R
package dependencies of Biomass_core, such as the LandR R package
and SpaDES, they also provide a means to test
module integration. We also implemented GitHub Actions continuous integration
(CI), which routinely test GitHub hosted packages (e.g., LandR) and modules.
CRAN-hosted packages (e.g., SpaDES) are also automatically tested and checked
on CRAN.
Finally, because Biomass_core (and all other LandR modules) code is hosted in public GitHub repositories, the module code is subject to the scrutiny of many users, who can identify issues and contribute to improve module code.
1.2.7.3 Performance and accuracy of Biomass_core with respect to LBSE
In the recoding of Biomass_core, we used integration tests to ensured similar outputs of each demographic process (namely, growth, mortality and recruitment) to the outputs from its counterpart in LBSE. Here, we report the comparisons of the overall simulation (i.e., including all demographic processes) between LBSE and Biomass_core using three randomly generated initial communities (Tables 1.10-1.12). The remaining input parameters were taken from a LANDIS-II training course (Tables 1.13-1.16), and contained species attributes information of 16 common tree species in boreal forests and 2 ecolocations. We ran simulations for 1000 years, with a succession time step of 10 and three replicates, which were enough to account for the variability produced by stochastic processes. Seed dispersal was set as “ward dispersal”.
The results suggested that Biomass_core had a good agreement with LBSE using the three randomly generated initial communities (Fig. 1.5), with very small deviations for LBSE-generated biomasses. Notably, the mean differences between LBSE and Biomass_core were 0.03% (range: -0.01% ~ 0.13%), 0.03% (range: -0.01% ~ 0.11%) and 0.05% (-0.02% ~ 0.15%) for each initial community, respectively (right panels in Fig. 1.5 of this appendix).
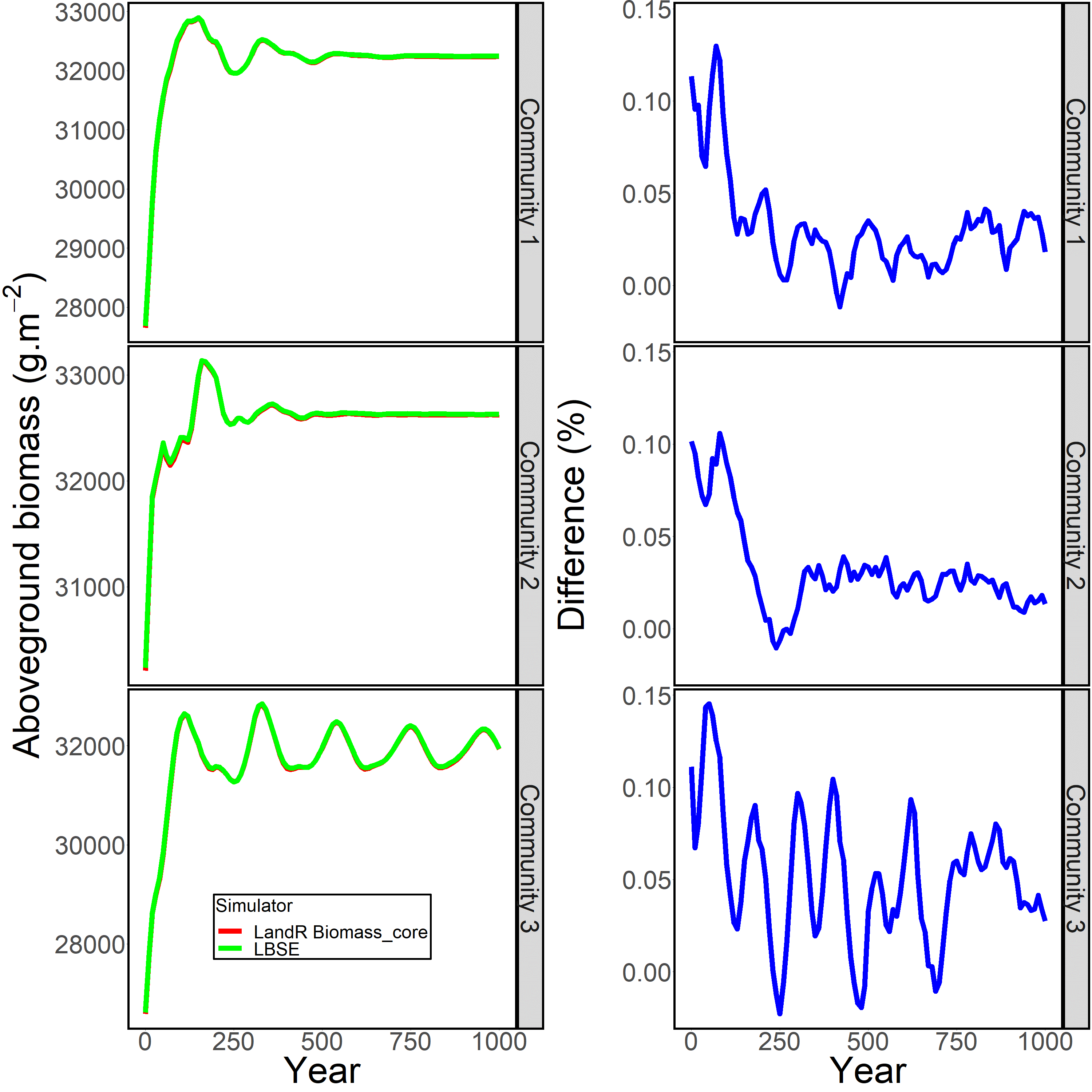
Figure 1.5: Visual comparison of simulation outputs for three randomly generated initial communities (left panels) and difference between those outputs (right panels). The % difference between LBSE and Biomass_core were calculated as \(\frac{Biomass_{LBSE} - Biomass_{Biomass_core}}{Biomass_{LBSE}} * 100\)
To examine how running time changed with map size, we ran simulations using maps with increasing number of pixels, from 22,201 to 638,401 pixels. All maps were initialised with a single ecolocation and 7 different communities. Simulations were run for 120 years using a succession time step of 10 and replicated three times. To eliminate the effect of hardware on running time, we used machines that were all purchased at the same time, with equal specifications and running Windows 7. Each simulation ran on 2 CPU threads with a total RAM of 4000 Mb.
For both LBSE and Biomass_core, the simulation time increased linearly with number of pixels, but the increase rate was smaller for Biomass_core (Fig. 1.6a). This meant that while both models had similar simulation efficiencies in small maps (< 90,000 pixels), as map size increased Biomass_core was ~2 times faster than LBSE (maps > 100,000 pixels; Fig. 1.6a). Biomass_core also scaled better with map size, as LBSE speeds fluctuated between 19 to 25 seconds per 1,000 pixels across all map sizes, while Biomass_core decreased from 21 to 11 seconds per 1,000 pixels from smaller to larger maps (Fig. 1.6b).
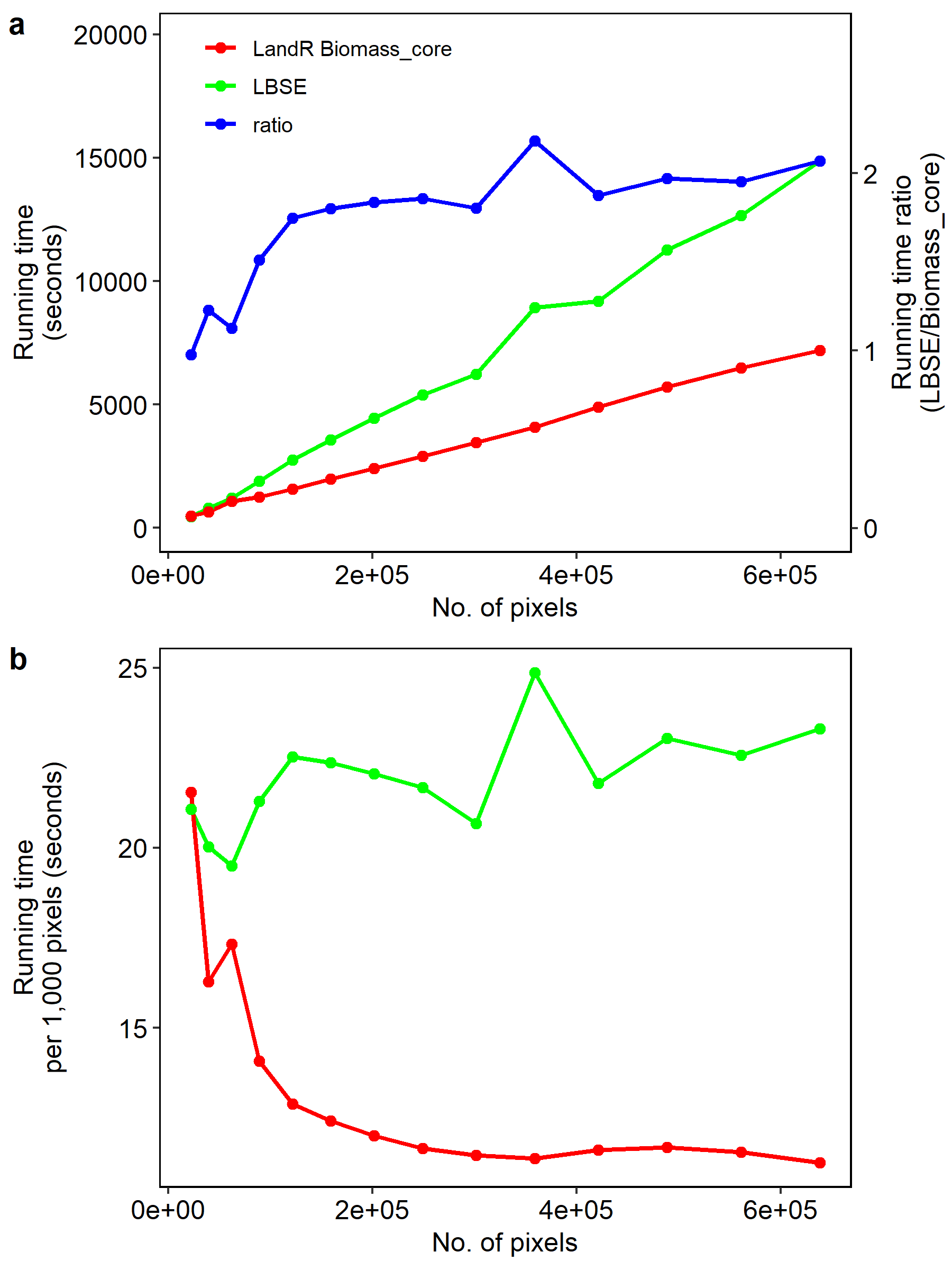
Figure 1.6: Simulation efficiencies of LBSE and Biomass_core with increasing map size, in terms of a) mean running time across repetitions (left y-axis) and the ratio LBSE to Biomass_core running times (right y-axis and blue line), and b) running time scalability as the mean running time per 1000 pixels.
1.3 Usage example
1.3.1 Set up R libraries
options(repos = c(CRAN = "https://cloud.r-project.org"))
tempDir <- tempdir()
pkgPath <- file.path(tempDir, "packages", version$platform, paste0(version$major,
".", strsplit(version$minor, "[.]")[[1]][1]))
dir.create(pkgPath, recursive = TRUE)
.libPaths(pkgPath, include.site = FALSE)
if (!require(Require, lib.loc = pkgPath)) {
remotes::install_github(paste0("PredictiveEcology/", "Require@5c44205bf407f613f53546be652a438ef1248147"),
upgrade = FALSE, force = TRUE)
library(Require, lib.loc = pkgPath)
}
setLinuxBinaryRepo()1.3.2 Get the module and module dependencies
We can use the SpaDES.project::getModule function to download the module to
the module folder specified above. Alternatively, see SpaDES-modules
repository to see how to
download this and other SpaDES modules, or fork/clone from its GitHub
repository directly.
After downloading the module, it is important to make sure all module R package
dependencies are installed in their correct version.
SpaDES.project::packagesInModules makes a list of necessary packages for all
modules in the paths$modulePath, and Require installs them.
Require(paste0("PredictiveEcology/", "SpaDES.project@6d7de6ee12fc967c7c60de44f1aa3b04e6eeb5db"),
require = FALSE, upgrade = FALSE, standAlone = TRUE)
paths <- list(inputPath = normPath(file.path(tempDir, "inputs")),
cachePath = normPath(file.path(tempDir, "cache")), modulePath = normPath(file.path(tempDir,
"modules")), outputPath = normPath(file.path(tempDir,
"outputs")))
SpaDES.project::getModule(modulePath = paths$modulePath, c("PredictiveEcology/Biomass_core@master"),
overwrite = TRUE)
## make sure all necessary packages are installed:
outs <- SpaDES.project::packagesInModules(modulePath = paths$modulePath)
Require(c(unname(unlist(outs)), "SpaDES"), require = FALSE, standAlone = TRUE)
## load necessary packages
Require(c("SpaDES", "LandR", "reproducible", "pemisc"), upgrade = FALSE,
install = FALSE)1.3.3 Setup simulation
Here we setup a simulation in a random study area, using any species within the
LandR::sppEquivalencies_CA table that can be found there (Biomass_core will
retrieve species % cover maps and filter present species). We also
define the colour coding used for plotting, the type of plots we what to produce
and choose to output cohortData tables every year – note that these are not
pixel-based, so to “spatialise” results a posteriori the pixelBroupMap must
also be saved.
Please see the lists of input objects, parameters and outputs for more information.
times <- list(start = 0, end = 30)
studyArea <- Cache(randomStudyArea, size = 1e+07) # cache this so it creates a random one only once on a machine
# Pick the species you want to work with – using the naming
# convention in 'Boreal' column of
# LandR::sppEquivalencies_CA
speciesNameConvention <- "Boreal"
speciesToUse <- c("Pice_Gla", "Popu_Tre", "Pinu_Con")
sppEquiv <- sppEquivalencies_CA[get(speciesNameConvention) %in%
speciesToUse]
# Assign a colour convention for graphics for each species
sppColorVect <- sppColors(sppEquiv, speciesNameConvention, newVals = "Mixed",
palette = "Set1")
## Usage example
modules <- as.list("Biomass_core")
objects <- list(studyArea = studyArea, sppEquiv = sppEquiv, sppColorVect = sppColorVect)
successionTimestep <- 10L
## keep default values for most parameters (omitted from
## this list)
parameters <- list(Biomass_core = list(sppEquivCol = speciesNameConvention,
successionTimestep = successionTimestep, .plots = c("screen",
"object"), .plotInitialTime = times$start, .plots = c("screen",
"png"), .saveInitialTime = times$start, .useCache = "init",
.useParallel = FALSE))
outputs <- data.frame(expand.grid(objectName = "cohortData",
saveTime = unique(seq(times$start, times$end, by = 1)), eventPriority = 1,
stringsAsFactors = FALSE))1.3.4 Run simulation
simInitAndSpades is a wrapper function that runs both simInit (which
initialises all modules) and spades (which runs all modules, i.e., their events),
to which pass all the necessary setup objects created above.
Below, we pass some useful reproducible options that control caching ("reproducible.useCache")
and where inputs should be downloaded to ("reproducible.destinationPath").
opts <- options(reproducible.useCache = TRUE, reproducible.destinationPath = paths$inputPath,
spades.useRequire = FALSE)
graphics.off()
mySim <- simInitAndSpades(times = times, params = parameters,
modules = modules, objects = objects, paths = paths, outputs = outputs,
debug = TRUE)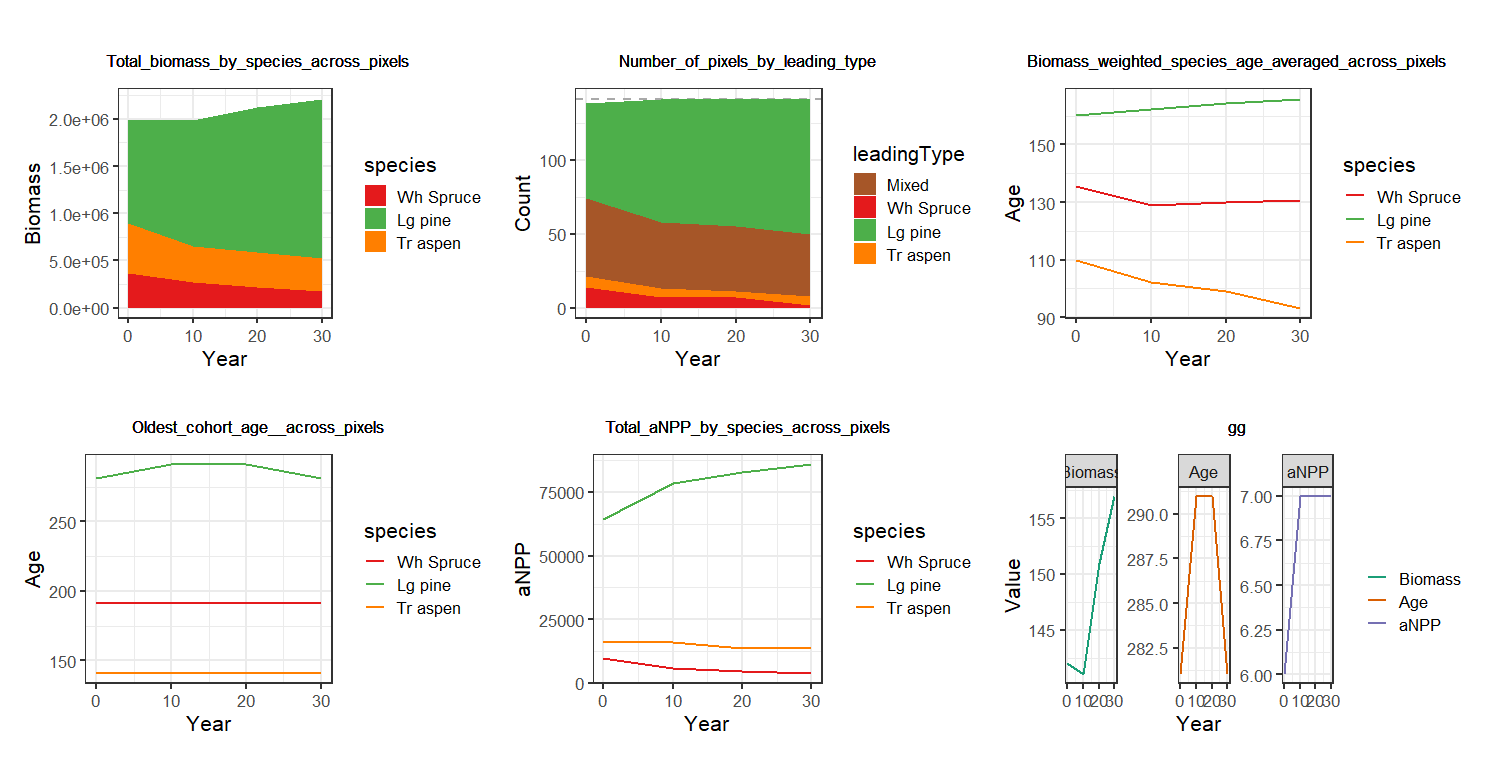
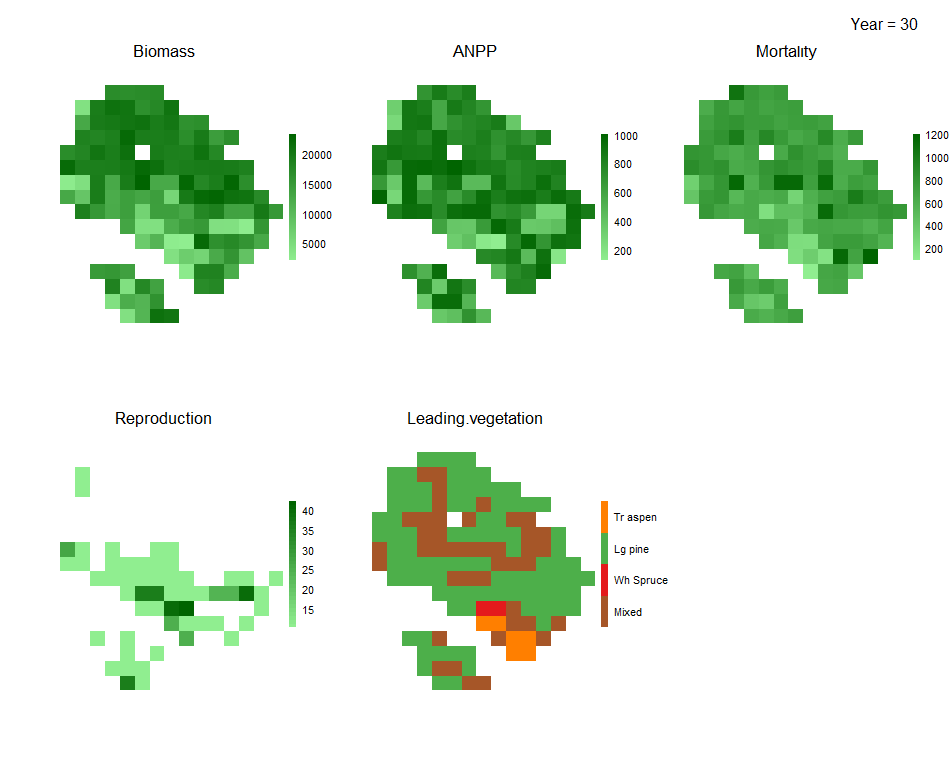
Figure 1.7: Biomass_core automatically generates simulation visuals of species dynamics across the landscape in terms of total biomass, number of presences and age and productivity (above), as well as yearly plots of total biomass, productivity, mortality, reproduction and leading species in each pixel (below).
1.4 Appendix
1.4.1 Tables
| Input order 1 | Input order 2 | ||||||
|---|---|---|---|---|---|---|---|
| Community | Input order | Age | Processing | Community | Input order | Age | Processing |
| 1 | abiebals | 20 | poputrem | 1 | pinustro | 20 | thujocci |
| 1 | acerrubr | 20 | querelli | 1 | poputrem | 20 | tiliamer |
| 1 | acersacc | 20 | pinuresi | 1 | acerrubr | 20 | querelli |
| 1 | betualle | 20 | pinustro | 1 | pinubank | 20 | querrubr |
| 1 | betupapy | 20 | tiliamer | 1 | betualle | 20 | betupapy |
| 1 | fraxamer | 20 | tsugcana | 1 | piceglau | 20 | fraxamer |
| 1 | piceglau | 20 | querrubr | 1 | pinuresi | 20 | tsugcana |
| 1 | pinubank | 20 | thujocci | 1 | acersacc | 20 | abiebals |
| 1 | pinuresi | 20 | acersacc | 1 | querelli | 20 | acerrubr |
| 1 | pinustro | 20 | betualle | 1 | querrubr | 20 | pinubank |
| 1 | poputrem | 20 | abiebals | 1 | thujocci | 20 | pinustro |
| 1 | querelli | 20 | acerrubr | 1 | tiliamer | 20 | poputrem |
| 1 | querrubr | 20 | piceglau | 1 | tsugcana | 20 | pinuresi |
| 1 | thujocci | 20 | pinubank | 1 | abiebals | 20 | acersacc |
| 1 | tiliamer | 20 | betupapy | 1 | betupapy | 20 | betualle |
| 1 | tsugcana | 20 | fraxamer | 1 | fraxamer | 20 | piceglau |
| Input order 1 | Input order 2 | ||||||
|---|---|---|---|---|---|---|---|
| Community | Input order | Age | Processing | Community | Input order | Age | Processing |
| 1 | abiebals | 1 | poputrem | 1 | pinustro | 1 | thujocci |
| 1 | acerrubr | 1 | querelli | 1 | poputrem | 1 | tiliamer |
| 1 | acersacc | 1 | pinuresi | 1 | acerrubr | 1 | querelli |
| 1 | betualle | 1 | pinustro | 1 | pinubank | 1 | querrubr |
| 1 | betupapy | 1 | tiliamer | 1 | betualle | 1 | betupapy |
| 1 | fraxamer | 1 | tsugcana | 1 | piceglau | 1 | fraxamer |
| 1 | piceglau | 1 | querrubr | 1 | pinuresi | 1 | tsugcana |
| 1 | pinubank | 1 | thujocci | 1 | acersacc | 1 | abiebals |
| 1 | pinuresi | 1 | acersacc | 1 | querelli | 1 | acerrubr |
| 1 | pinustro | 1 | betualle | 1 | querrubr | 1 | pinubank |
| 1 | poputrem | 1 | abiebals | 1 | thujocci | 1 | pinustro |
| 1 | querelli | 1 | acerrubr | 1 | tiliamer | 1 | poputrem |
| 1 | querrubr | 1 | piceglau | 1 | tsugcana | 1 | pinuresi |
| 1 | thujocci | 1 | pinubank | 1 | abiebals | 1 | acersacc |
| 1 | tiliamer | 1 | betupapy | 1 | betupapy | 1 | betualle |
| 1 | tsugcana | 1 | fraxamer | 1 | fraxamer | 1 | piceglau |
| Community | Species | Age 1 | Age 2 | Age 3 | Age 4 | Age 5 | Age 6 | Age 7 |
|---|---|---|---|---|---|---|---|---|
| 0 | betupapy | 1 | 37 | 45 | 46 | 85 | NA | NA |
| 0 | piceglau | 27 | 73 | 153 | 256 | 270 | NA | NA |
| 0 | pinustro | 157 | 159 | 181 | 220 | 223 | 303 | 307 |
| 0 | querrubr | 80 | 102 | 127 | 152 | 206 | 227 | NA |
| 1 | acerrubr | 3 | 91 | 126 | 145 | NA | NA | NA |
| 1 | acersacc | 138 | 144 | 276 | NA | NA | NA | NA |
| 1 | betualle | 24 | 106 | 136 | 149 | 279 | NA | NA |
| 1 | piceglau | 27 | 67 | 70 | 153 | NA | NA | NA |
| 1 | pinubank | 3 | 10 | 24 | 31 | 71 | NA | NA |
| 1 | querelli | 92 | 224 | 234 | NA | NA | NA | NA |
| 1 | thujocci | 73 | 146 | 262 | NA | NA | NA | NA |
| 2 | fraxamer | 108 | 118 | 137 | 147 | 204 | NA | NA |
| 2 | piceglau | 40 | 128 | 131 | 159 | 174 | NA | NA |
| 2 | pinustro | 78 | 156 | 237 | 245 | 270 | NA | NA |
| 2 | querelli | 67 | 97 | 186 | 292 | NA | NA | NA |
| 2 | tiliamer | 70 | 103 | 121 | 152 | 178 | 180 | 245 |
| 3 | acerrubr | 5 | 83 | 125 | 126 | 127 | NA | NA |
| 3 | pinuresi | 1 | 25 | 42 | 49 | 76 | 79 | 103 |
| 3 | poputrem | 4 | 9 | 62 | NA | NA | NA | NA |
| 3 | querelli | 101 | 104 | 167 | 226 | NA | NA | NA |
| 3 | tsugcana | 37 | 135 | 197 | 404 | 405 | NA | NA |
| 4 | acerrubr | 15 | 29 | 63 | 70 | 105 | 133 | NA |
| 4 | piceglau | 67 | 132 | 189 | NA | NA | NA | NA |
| 4 | tsugcana | 21 | 26 | 110 | 146 | 341 | 462 | 463 |
| 5 | acerrubr | 128 | 137 | 145 | 147 | NA | NA | NA |
| 5 | acersacc | 241 | 245 | 261 | 277 | NA | NA | NA |
| 5 | querrubr | 23 | 72 | 120 | 142 | 188 | NA | NA |
| 5 | tiliamer | 4 | 68 | 98 | 118 | 139 | 197 | NA |
| 6 | betualle | 5 | 23 | 31 | 249 | NA | NA | NA |
| 6 | pinubank | 67 | 70 | 89 | NA | NA | NA | NA |
| 6 | querelli | 194 | 217 | 257 | NA | NA | NA | NA |
| Community | Species | Age 1 | Age 2 | Age 3 | Age 4 | Age 5 | Age 6 | Age 7 |
|---|---|---|---|---|---|---|---|---|
| 0 | acerrubr | 22 | 26 | 30 | 40 | 47 | 145 | 146 |
| 0 | betualle | 23 | 41 | 43 | 120 | 209 | 227 | 270 |
| 0 | fraxamer | 25 | 90 | 119 | 173 | 185 | 282 | NA |
| 0 | pinuresi | 48 | 53 | 70 | 121 | 157 | NA | NA |
| 0 | pinustro | 5 | 82 | 126 | 298 | 352 | NA | NA |
| 0 | querrubr | 2 | 30 | 34 | 74 | 77 | 162 | 245 |
| 1 | acerrubr | 2 | 39 | 43 | 84 | 116 | 127 | 143 |
| 1 | pinubank | 34 | 57 | 75 | NA | NA | NA | NA |
| 1 | querelli | 108 | 202 | 218 | 243 | NA | NA | NA |
| 1 | querrubr | 5 | 117 | 131 | 186 | 189 | 246 | NA |
| 1 | tiliamer | 10 | 19 | 46 | 80 | 133 | 148 | 231 |
| 1 | tsugcana | 31 | 48 | 190 | 246 | 330 | NA | NA |
| 2 | pinubank | 11 | 37 | 38 | 47 | 67 | 93 | NA |
| 2 | querrubr | 11 | 48 | 57 | 177 | 180 | 228 | 236 |
| 2 | tiliamer | 28 | 42 | 78 | 79 | 223 | 250 | NA |
| 2 | tsugcana | 140 | 202 | 372 | 381 | 451 | NA | NA |
| 3 | acersacc | 48 | 107 | 262 | 265 | NA | NA | NA |
| 3 | betupapy | 4 | 12 | 45 | 65 | 83 | 96 | NA |
| 3 | poputrem | 13 | 20 | 37 | 75 | 90 | NA | NA |
| 3 | querelli | 72 | 90 | 104 | 115 | 116 | 265 | 278 |
| 3 | tiliamer | 20 | 21 | 56 | 98 | 237 | NA | NA |
| 3 | tsugcana | 86 | 224 | 425 | 429 | NA | NA | NA |
| 4 | fraxamer | 77 | 133 | 181 | NA | NA | NA | NA |
| 4 | pinustro | 13 | 37 | 67 | 220 | 287 | 293 | 375 |
| 4 | querrubr | 27 | 48 | 89 | 97 | NA | NA | NA |
| 4 | thujocci | 91 | 244 | 305 | 390 | NA | NA | NA |
| 5 | abiebals | 86 | 95 | 119 | 121 | 127 | 158 | NA |
| 5 | betualle | 83 | 113 | 136 | 161 | 216 | 231 | NA |
| 5 | betupapy | 10 | 38 | 64 | NA | NA | NA | NA |
| 5 | piceglau | 16 | 63 | 70 | 102 | NA | NA | NA |
| 6 | acerrubr | 8 | 34 | 112 | NA | NA | NA | NA |
| 6 | betupapy | 1 | 31 | 57 | 61 | 74 | 80 | 91 |
| 6 | fraxamer | 63 | 100 | 108 | 140 | 196 | 294 | NA |
| 6 | pinubank | 15 | 19 | 44 | 47 | 51 | 80 | NA |
| 6 | thujocci | 78 | 146 | 163 | 213 | 214 | 228 | NA |
| 6 | tsugcana | 47 | 108 | 387 | 389 | 449 | NA | NA |
| Community | Species | Age 1 | Age 2 | Age 3 | Age 4 | Age 5 | Age 6 | Age 7 |
|---|---|---|---|---|---|---|---|---|
| 0 | pinubank | 7 | 26 | 32 | 37 | 48 | 85 | 90 |
| 0 | pinuresi | 11 | 103 | 109 | 179 | 188 | 197 | NA |
| 0 | querrubr | 89 | 139 | 180 | 206 | NA | NA | NA |
| 1 | betupapy | 36 | 39 | 45 | 49 | 66 | 68 | NA |
| 1 | piceglau | 13 | 165 | 254 | NA | NA | NA | NA |
| 1 | pinubank | 3 | 19 | 54 | 64 | 76 | NA | NA |
| 1 | poputrem | 22 | 59 | 93 | NA | NA | NA | NA |
| 1 | thujocci | 68 | 98 | 274 | 275 | 363 | 378 | NA |
| 1 | tiliamer | 13 | 20 | 105 | 124 | 248 | NA | NA |
| 1 | tsugcana | 36 | 90 | 142 | NA | NA | NA | NA |
| 2 | fraxamer | 11 | 241 | 279 | NA | NA | NA | NA |
| 2 | piceglau | 16 | 42 | 129 | 177 | 200 | 244 | NA |
| 2 | pinustro | 200 | 342 | 384 | NA | NA | NA | NA |
| 3 | abiebals | 31 | 57 | 61 | 92 | 108 | 162 | 183 |
| 3 | piceglau | 126 | 255 | 261 | 267 | NA | NA | NA |
| 3 | poputrem | 28 | 41 | 57 | NA | NA | NA | NA |
| 3 | querrubr | 83 | 91 | 144 | 173 | 184 | 238 | NA |
| 3 | thujocci | 6 | 66 | 68 | 204 | NA | NA | NA |
| 4 | fraxamer | 12 | 110 | 266 | 270 | NA | NA | NA |
| 4 | pinustro | 174 | 270 | 359 | 379 | NA | NA | NA |
| 4 | poputrem | 4 | 7 | 18 | 24 | 63 | 76 | NA |
| 4 | tiliamer | 126 | 136 | 197 | NA | NA | NA | NA |
| 4 | tsugcana | 49 | 91 | 128 | 194 | 411 | 487 | NA |
| 5 | abiebals | 35 | 53 | 108 | 114 | 147 | 174 | 195 |
| 5 | acerrubr | 1 | 2 | 101 | 145 | NA | NA | NA |
| 5 | pinubank | 14 | 15 | 38 | 40 | 59 | 69 | 83 |
| 6 | acerrubr | 4 | 46 | 117 | NA | NA | NA | NA |
| 6 | betualle | 36 | 41 | 116 | 213 | 253 | NA | NA |
| 6 | betupapy | 4 | 6 | 76 | NA | NA | NA | NA |
| 6 | pinuresi | 43 | 68 | 85 | 171 | NA | NA | NA |
| 6 | querrubr | 84 | 86 | 113 | 185 | 193 | 223 | 228 |
| 6 | tiliamer | 13 | 106 | 181 | 199 | 246 | NA | NA |
| Species | Longevity | Sexualmature | Shadetolerance | Seeddistance_eff | Seeddistance_max | Mortalityshape | Growthcurve |
|---|---|---|---|---|---|---|---|
| abiebals | 200 | 25 | 5 | 30 | 160 | 10 | 0.25 |
| acerrubr | 150 | 10 | 4 | 100 | 200 | 10 | 0.25 |
| acersacc | 300 | 40 | 5 | 100 | 200 | 10 | 0.25 |
| betualle | 300 | 40 | 4 | 100 | 400 | 10 | 0.25 |
| betupapy | 100 | 30 | 2 | 200 | 5000 | 10 | 0.25 |
| fraxamer | 300 | 30 | 4 | 70 | 140 | 10 | 0.25 |
| piceglau | 300 | 25 | 3 | 30 | 200 | 10 | 0.25 |
| pinubank | 100 | 15 | 1 | 20 | 100 | 10 | 0.25 |
| pinuresi | 200 | 35 | 2 | 20 | 275 | 10 | 0.25 |
| pinustro | 400 | 40 | 3 | 60 | 210 | 10 | 0.25 |
| poputrem | 100 | 20 | 1 | 1000 | 5000 | 10 | 0.25 |
| querelli | 300 | 35 | 2 | 30 | 3000 | 10 | 0.25 |
| querrubr | 250 | 25 | 3 | 30 | 3000 | 10 | 0.25 |
| thujocci | 400 | 30 | 2 | 45 | 60 | 10 | 0.25 |
| tiliamer | 250 | 30 | 4 | 30 | 120 | 10 | 0.25 |
| tsugcana | 500 | 30 | 5 | 30 | 100 | 10 | 0.25 |
| Ecolocation | X0 | X1 | X2 | X3 | X4 | X5 |
|---|---|---|---|---|---|---|
| All | 0 | 0.15 | 0.25 | 0.5 | 0.8 | 0.95 |
| Shadetolerance | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 1 | 0 | 0 | 0 | 0 |
| 3 | 1 | 1 | 1 | 0 | 0 | 0 |
| 4 | 1 | 1 | 1 | 1 | 0 | 0 |
| 5 | 0 | 0 | 1 | 1 | 1 | 1 |
| Ecolocation | Species | SEP | maxANPP | maxB |
|---|---|---|---|---|
| 1 | abiebals | 0.90 | 886 | 26580 |
| 1 | acerrubr | 1.00 | 1175 | 35250 |
| 1 | acersacc | 0.82 | 1106 | 33180 |
| 1 | betualle | 0.64 | 1202 | 36060 |
| 1 | betupapy | 1.00 | 1202 | 36060 |
| 1 | fraxamer | 0.18 | 1202 | 36060 |
| 1 | piceglau | 0.58 | 969 | 29070 |
| 1 | pinubank | 1.00 | 1130 | 33900 |
| 1 | pinuresi | 0.56 | 1017 | 30510 |
| 1 | pinustro | 0.72 | 1090 | 38150 |
| 1 | poputrem | 1.00 | 1078 | 32340 |
| 1 | querelli | 0.96 | 1096 | 32880 |
| 1 | querrubr | 0.66 | 1017 | 30510 |
| 1 | thujocci | 0.76 | 1090 | 32700 |
| 1 | tiliamer | 0.54 | 1078 | 32340 |
| 1 | tsugcana | 0.22 | 1096 | 32880 |
in LBSE the initialisation consists in “iterat[ing] the number of time steps equal to the maximum cohort age for each site”, beginning at 0 minus t (t = oldest cohort age) and adding cohorts at the appropriate time until the initial simulation time is reached (0) (Scheller & Miranda 2015b).↩︎
usually, default inputs are made when running the
.inputObjectsfunction (inside the module R script) during thesimInitcall and in theinitevent during thespadescall – see?SpaDES.core::eventsandSpaDES.core::simInit↩︎in
SpaDESlingo parameters are “small” objects, such as an integer or boolean, that can be controlled via theparametersargument insimInit.↩︎simInitis aSpaDESfunction that initialises the execution of one or more modules by parsing and checking their code and executing the.inputObjectsfunction(s), where the developer provides mechanisms to satisfy each module’s expected inputs with default values.↩︎